
慧眼识珠:开源OCR利器gImageReader使用教程

前文《神器魔手:Linux下光学字符识别利器OCRFeeder上手教程》介绍了站长薄荷君曾使用过的 OCRFeeder+Tesseract 软件,作为 OCR 识别软件,将图片、PDF 中的文字转换为可编辑的文字。但是经过实测,OCRFeeder 这个前端软件可能“年久失修”,竟然无法打开 PDF 了(2016 年薄荷君测试时都可以打开 PDF 文档)。虽然可以按照《图像魔术:ImageMagick轻松转换PDF和图片》文中的方法,先把 PDF 转换成图片,再用 OCRFeeder 识别文字,但是太繁琐了。
经过一番搜索,发现了多个同类的 OCR 软件,经过对比实测,站长薄荷君大力推荐新的开源 OCR 利器:gImageReader。
gImageReader 与 OCRFeeder 类似,都属于 OCR 前端软件,后台仍然需要 Tesseract 作为 OCR 识别引擎。因此,安装 gImageReader 的同时,也需要安装 Tesseract 及中文数据包。
以 LinuxMint 20.x/Ubuntu 20.04 为例,直接在终端中使用如下命令,安装 gImageReader 和 Tesseract。
sudo apt install gimagereader tesseract-ocr-chi-sim

启动 gImageReader,界面简洁,但是属于比较现代的界面布局风格,没有传统的菜单栏。看上去比 OCRFeeder 要好一些。

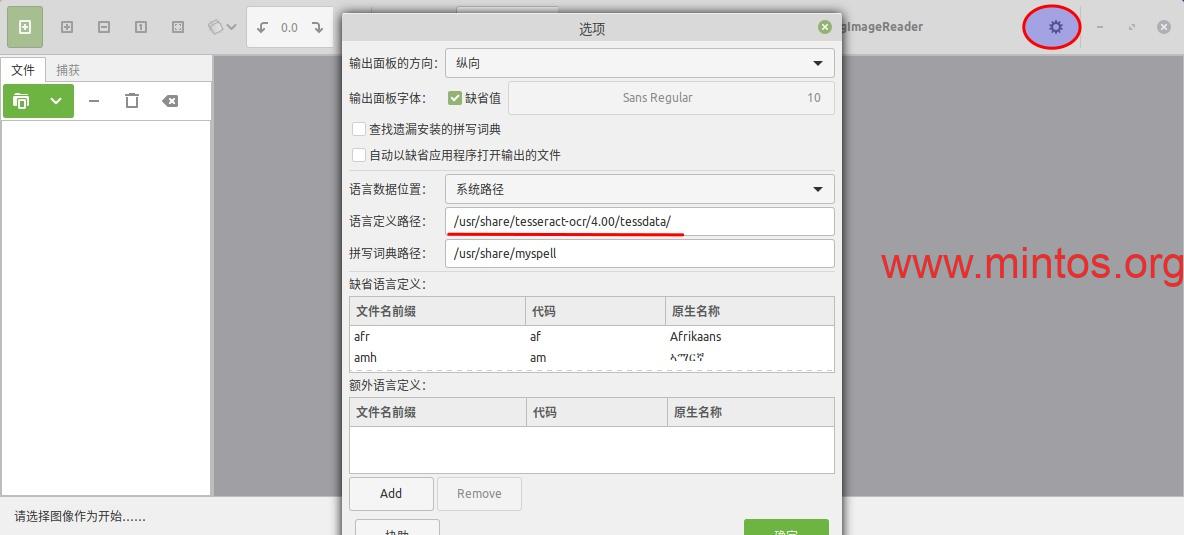
使用 gImageReader 之前,先点击右上角的齿轮按捺,看看 Tesseract 识别引擎配置是否正确。一般而言,只要安装了 Tesseract 和相应语言的数据包,gImageReader 会自动配置好,无需用户干预。
打开一个使用“扫描全能王”之类的拍照扫描合成 PDF 软件制作的 PDF 文档,看看 gImageReader 的识别能力如何。只要打开含有文字的图片或 PDF,gImageReader 都会有提示。

gImageReader 能够正常打开 PDF。

点击顶部的识别按钮,可以进行“现时页面”(当前页面)和多页识别。

薄荷君使用多页识别。gImageReader 会提示可以进行识别页码范围选择。如果不选择,直接点击确定,则识别文档全部页面。

如图所示,这是正在识别。底部两侧分别会显示识别的页数和进度条。

识别的同时,右侧就会出现识别出的文字内容。识别结束,可以选中已识别出来的文字,进行简单编辑、修正。gImageReader 提供了一组实用的编辑工具。如图所示,去除换行。

选中全部文字,去除换行。对比上图可知,去除了很多错误的换行,效果好多了。

然后点击“存储输出”,可以把识别结果保存为 txt 文本文件。

非常贴心的是,gImageReader 输出保存的文本文件与原来的 PDF 文件同名,免去了手动改名的麻烦。

小结:经过实测,gImageReader 无论界面还是功能,都比 OCRFeeder 强多了,薄荷君决定将 gImageReader 作为日常办公必备软件之一。



